Reading Reflection on the Bigtable Paper
Introduction
After MapReduce and GFS, I finally finished reading the last of Google's three foundational papers – Bigtable. Similar to Dynamo, many techniques described in the Bigtable paper have been widely adopted by various subsequent projects, so reading it felt familiar. This post will comprehensively discuss Bigtable's programming model, underlying storage, workflow, performance, and other aspects.
Programming Model
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map. The map is indexed by a row key, column key, and a timestamp;
This definition can be a bit tricky to grasp. Although Bigtable is a NoSQL database, it provides a semi-structured data model, allowing us to draw an analogy to an RDBMS. For a table, row can be thought of as the primary key for a row, column as the field name for a column, and time as a version number for this row. The mapped string value is the field value for that specific row and column.
The most significant difference here is the concept of custom columns, which makes Bigtable highly flexible in usage. While Bigtable does not limit the number of columns, it requires that every column belongs to a column family, and the number of column families is limited. A column family is a collection of columns serving a common purpose. Users can configure various properties for a column family, such as access control, whether to cache it in memory, etc. Therefore, from a user's perspective, one must first create a column family family and then reference it when specifying a column using the format family:columnKey. In a way, a Bigtable column family corresponds to a column in an RDBMS; these are the table's metadata.
row is similar to a primary key in an RDBMS: it uniquely identifies a row; rows are stored sorted by their row value. Tables in Bigtable are horizontally partitioned by row ranges. Each partition is called a tablet, storing rows corresponding to a contiguous range of row values. A tablet is stored on a single node. Consequently, rows with similar row values will belong to only a few tablets, meaning a single query only needs to communicate with a small number of nodes, resulting in higher efficiency.
The time version number typically uses the current timestamp provided by Bigtable, although programs can also define custom timestamps. Bigtable provides two version retention policies: (1) keep only the latest n versions, or (2) keep only versions from the last t seconds.
In addition to ordinary metadata operations and read/write operations, the Bigtable client API includes:
- Single-row "transactions": A series of read/write operations on a single row are atomic. This transaction model is similar to Redis transactions, guaranteeing atomicity for performing a sequence of operations but not providing interactive transactions with the program. Bigtable does not offer multi-row transactions.
- Execution of Sawzall read-only scripts (Sawzall is a scripting language developed by Google). This functionality is akin to Redis executing Lua scripts, but these scripts can only perform read operations and data transformations, not write operations.
Bigtable can also be integrated with MapReduce, serving as a data source or sink.
Architecture
There are two types of tables in Bigtable: metadata tables and user-defined tables. All tables are horizontally partitioned into multiple tablets. Metadata tables store which tablet server each tablet is assigned to. All tablets are stored on GFS, so GFS holds the tablet assignment information.
Bigtable employs a classic master-slave architecture, with one master node and multiple worker nodes (tablet servers). Additionally, Bigtable relies on the Chubby service (a distributed lock service, similar to a distributed coordination service like ZooKeeper). Chubby ensures a single master, implements service discovery for tablet servers, stores table metadata, and provides other functions.
The master node is responsible for managing and maintaining tablet assignments, monitoring tablet server status, performing garbage collection, handling metadata changes, and other administrative tasks. It does not store any data itself. Tablet servers manage the tablets assigned to them and handle read/write operations for those tablets.
Unlike GFS, where the master stores metadata, Bigtable's metadata is stored in GFS and Chubby. This design means Bigtable clients rarely need to communicate with the master node, significantly reducing the load on the master.
Underlying Implementation
Bigtable leverages GFS for reliable, distributed file storage, freeing Bigtable from worrying about low-level details. However, GFS is not a general-purpose file system, and the efficiency of different operations varies. It's worth recalling GFS's design goals: it's primarily optimized for sequential reads and writes of large files, focusing on high throughput. This implies that operations on small files, random reads/writes, and latency are not its strengths. Bigtable's implementation must account for these GFS characteristics to deliver optimal performance.
Bigtable draws inspiration from LSM-tree concepts. The composition and workflow of each tablet are illustrated below:
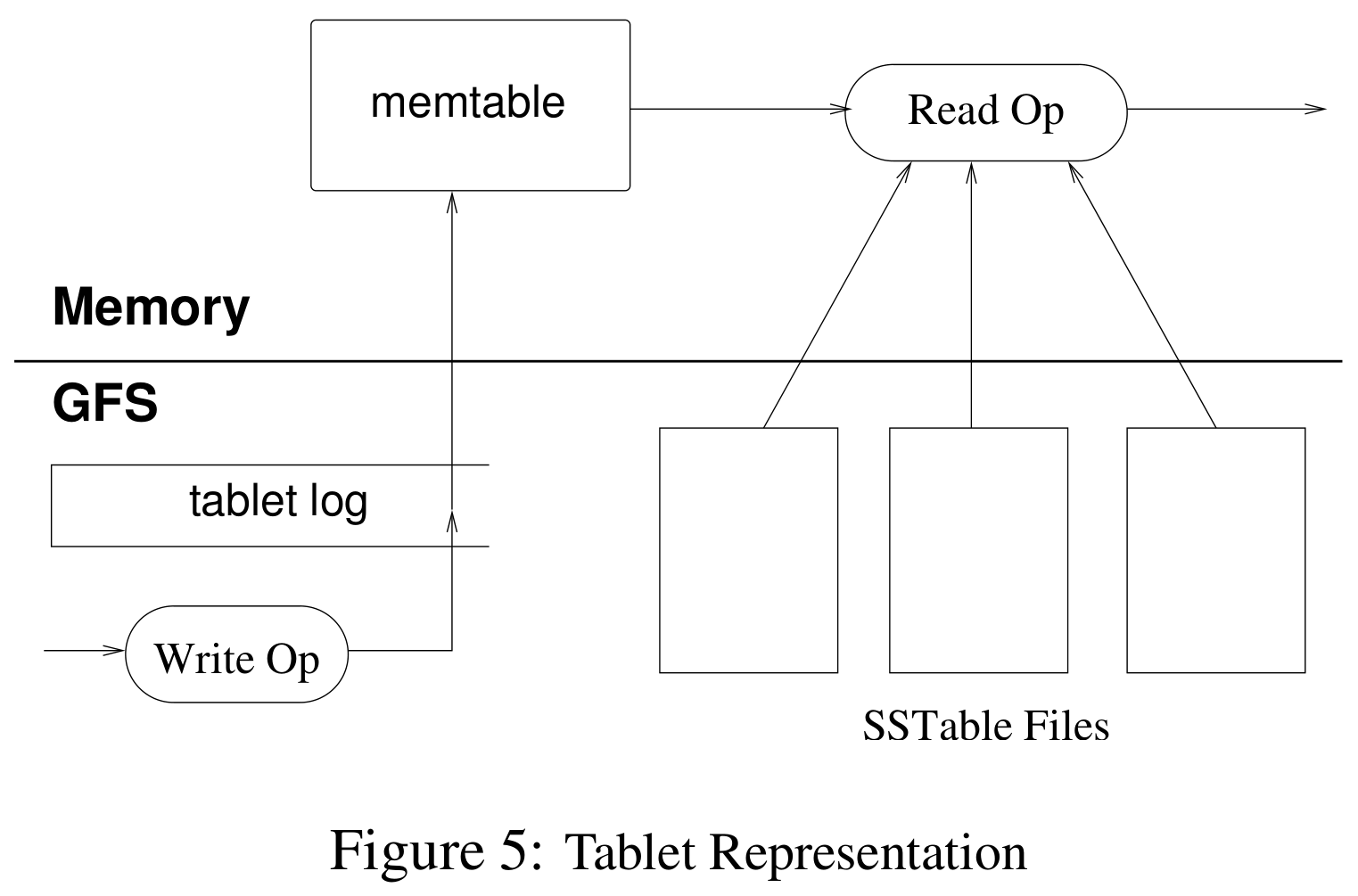
SSTable files are immutable and store sorted key-value pairs. Physically, each SSTable is divided into multiple 64KB blocks (block size is configurable) and includes a block index. To find a key-value pair in an SSTable, a binary search is first performed on the block index to locate the relevant block. That block is then read to find the target key-value pair. Typically, the block index resides in memory, meaning each key-value read requires only one disk access.
The memtable is an in-memory sorted buffer that also stores key-value pairs.
For write operations: first, write to the commit log; after that succeeds, modify the memtable, and then return success. This uses Write-Ahead Logging (WAL) technology, converting random writes into sequential writes. WAL is commonly used in databases where the storage medium is HDD. Since GFS shares similar characteristics in this context, Bigtable also employs this technique.
For read operations: both the memtable and SSTables need to be queried. The search typically proceeds from newest to oldest (memtable, then newest SSTable, etc.) until the key-value data is first found in one of these tables. Although both types of tables are sorted, reading multiple SSTable blocks from disk can still occur, leading to lower read efficiency. This is why LSM-tree-based databases are often suitable for write-heavy, read-light scenarios. Of course, Bigtable includes many optimizations: caching key-value pairs, caching SSTable blocks, keeping data for specific column families permanently in memory, and setting up Bloom filters for certain columns.
When the memtable reaches a certain size, it is converted into an SSTable and written to GFS. Simultaneously, a redo point (i.e., a checkpoint) is recorded in the commit log, and a new memtable is created. This process not only reduces memory usage but also aids in speeding up recovery. During recovery, a tablet server reads the commit log starting from the latest redo point to rebuild the memtable. Operations before that redo point have already been persisted to SSTables and do not need recovery. Furthermore, Bigtable periodically merges some or all SSTables.
Performance
Although I've read the Borg paper and learned about Kubernetes, I tended to think these underlying services were deployed on dedicated servers. The Bigtable paper explicitly states that the experimental environment was a GFS cluster where each machine ran a GFS process. Some of these machines also ran tablet servers or Bigtable clients. Any machine could potentially run other processes. In other words, processes for different tasks shared server resources; there were no dedicated servers. This concrete example corrects my mistaken view.
Performance test data is as follows:
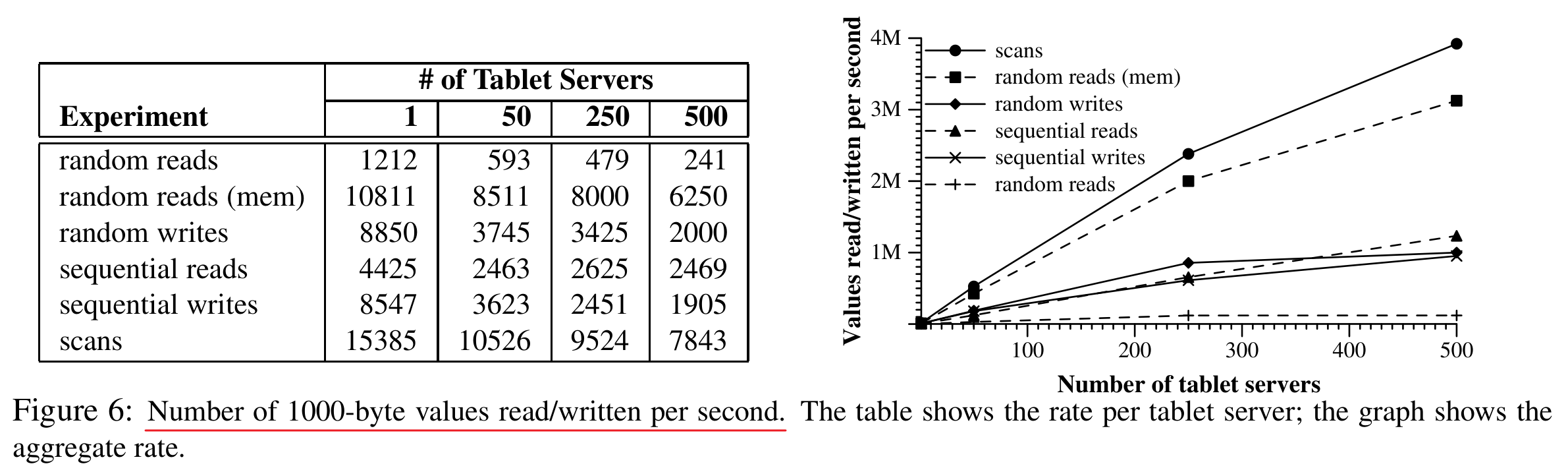
- Due to the LSM-tree-like mechanism, write performance is better than read performance.
- Random read performance is the worst because each read requires fetching an SSTable block from GFS, putting significant pressure on the tablet server's CPU and network I/O, as well as on the overall cluster network. Storing data in memory can significantly improve QPS.
- Sequential and random write performance is the same, as both are handled using WAL.
- Bigtable's horizontal scaling performance is quite good. Performance improvement scales roughly proportionally with the increase in the number of tablet servers. Although linear scaling is the theoretically optimal, in practice, it's constrained by competition for CPU and network I/O resources from other processes on the servers, and the overall cluster network bandwidth is also finite.
The following figure shows the usage of Bigtable by several Google production projects:
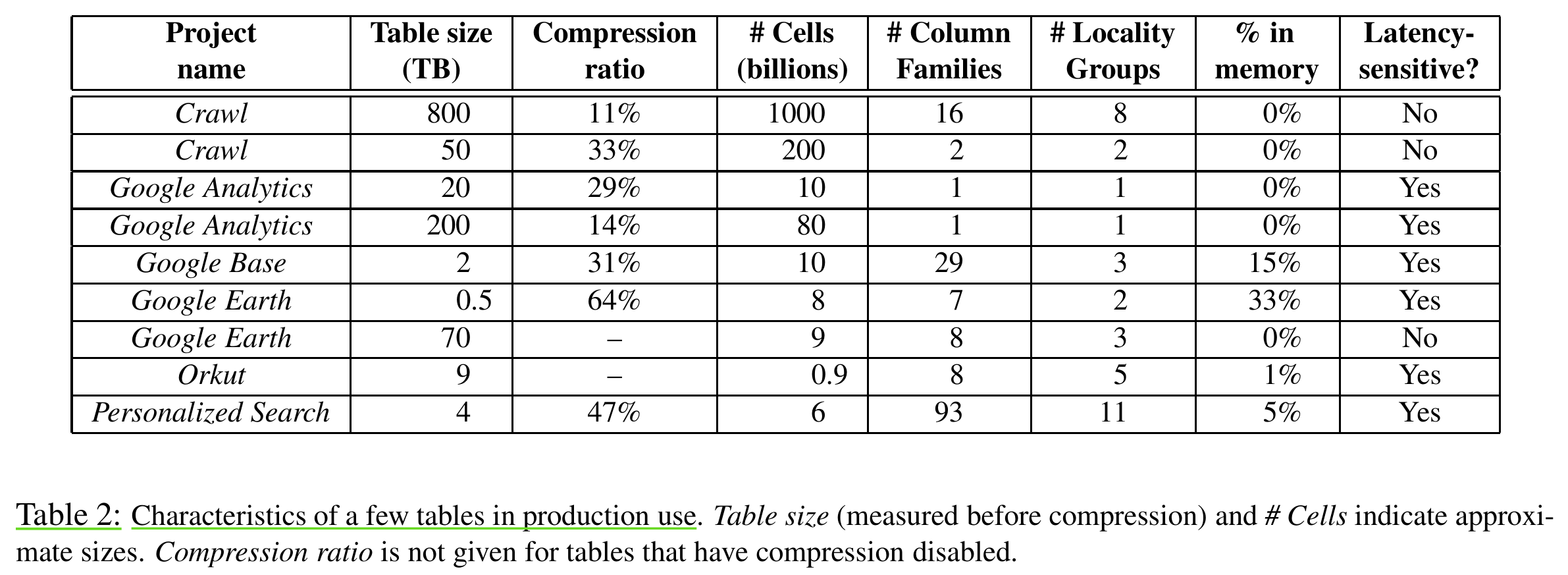
I'm particularly interested in latency here. Optimizations employed by these production projects to address latency include:
- Storing data in memory.
- Using more tablet servers to reduce the load on any single server.
- Replicating the same data to multiple geographically distributed Bigtable clusters for low-latency access.
However, neither the GFS nor the Bigtable paper provides specific latency numbers, so I remain curious and skeptical about the actual latency characteristics.
References
- Bigtable: A Distributed Storage System for Structured Data
- The Google File System