Reading Reflection on the Aurora Paper
Introduction
Amazon Aurora is a cloud-native, storage-compute separated database that offers significantly superior performance and scalability compared to traditional RDBMS. The compute layer of Aurora is based on open-source MySQL code, but delegates its logging, storage, and recovery modules to the storage layer. Compute nodes send redo logs to storage nodes, which persist the logs using a quorum protocol, resembling the replicated state machine model of consensus algorithms. Aurora's innovative design reduces network I/O in cloud environments by an order of magnitude and drastically cuts down the time for expensive operations like recovery.
From a learning perspective, this paper is good. It progressively presents various problems and their solutions with strong logical flow. Furthermore, for each technical point, it first explains the RDBMS approach and its shortcomings before detailing Aurora's implementation. However, I found reading this paper somewhat challenging. First, it carries a distinct commercial promotional tone, containing many glossy marketing phrases, a few customer stories, etc. Second, most papers I've read are in the system area, and I'm less familiar with many database-specific terms.
This article will cover Aurora's performance, architecture, consistency principles, and various technical details.
Performance
Let's first look at Aurora's impressive performance.
Aurora's compute nodes achieve linear vertical scaling: every time the machine's memory and CPU count double, Aurora's QPS and TPS also double. This indicates that Aurora's bottleneck is not I/O.
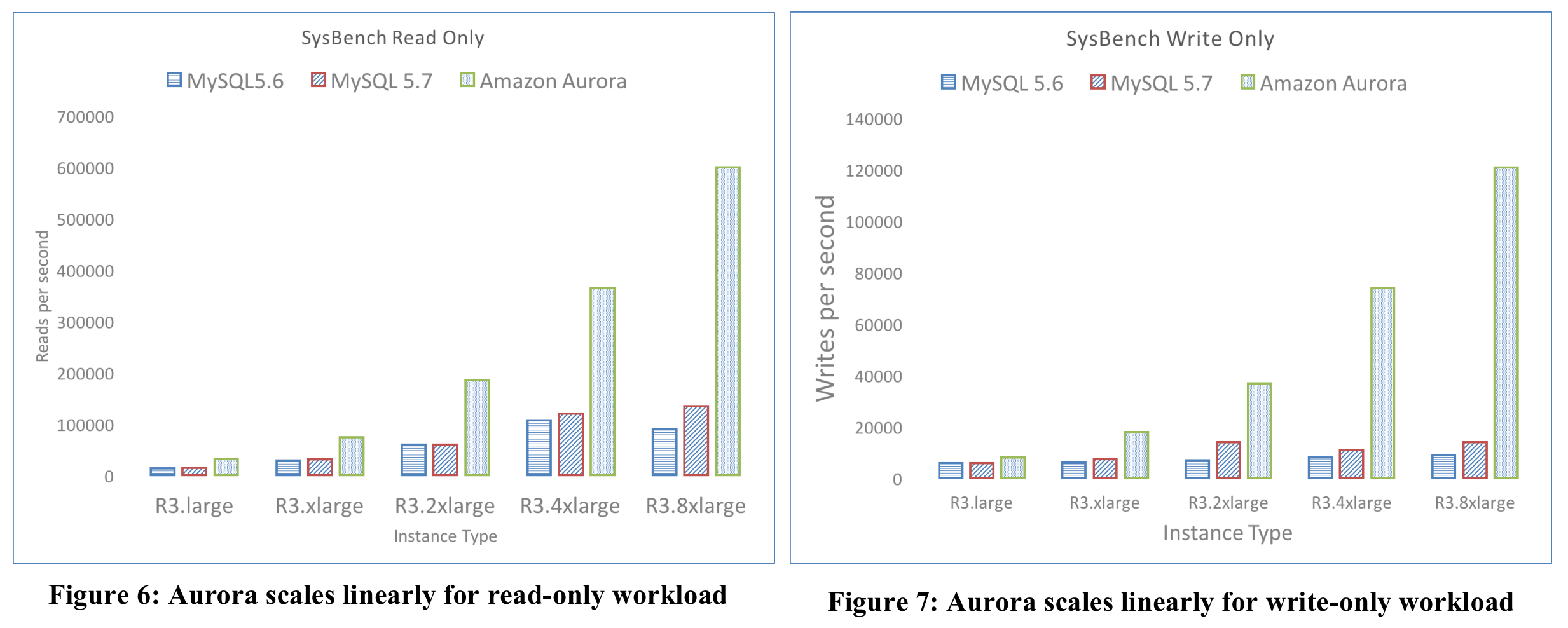
MySQL's storage model is based on B+ trees. When a table stores too much data, both read and write performance degrade. Although Aurora's write performance also declines, the rate of degradation is far slower than MySQL's.
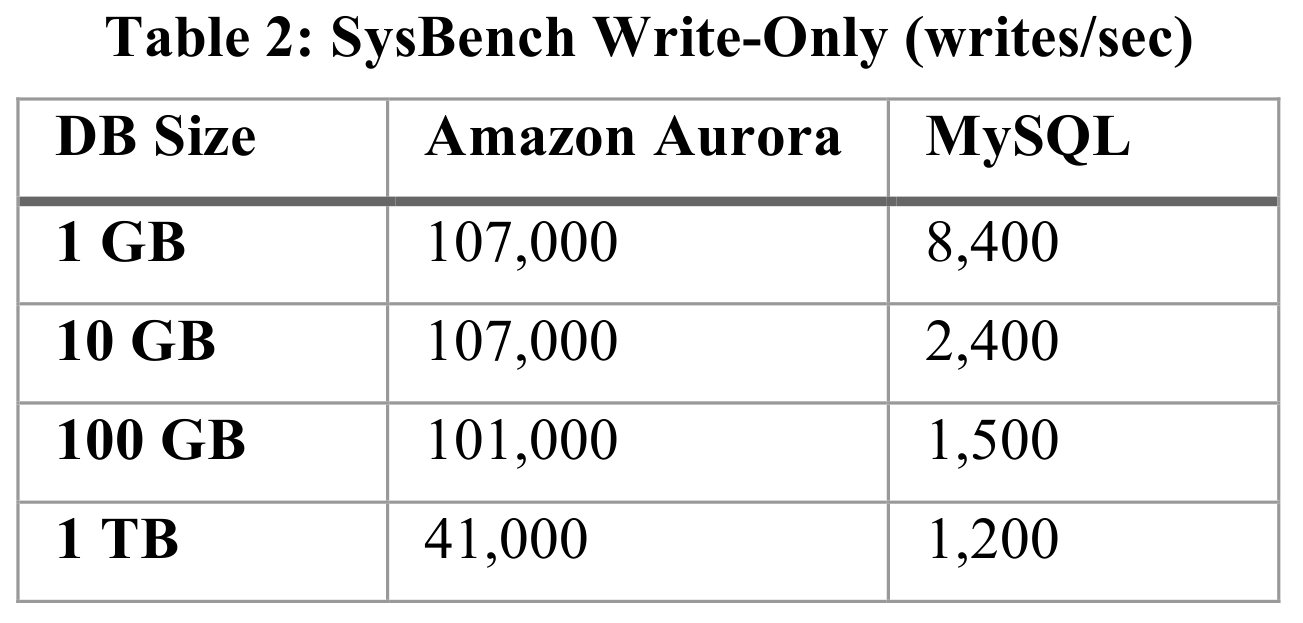
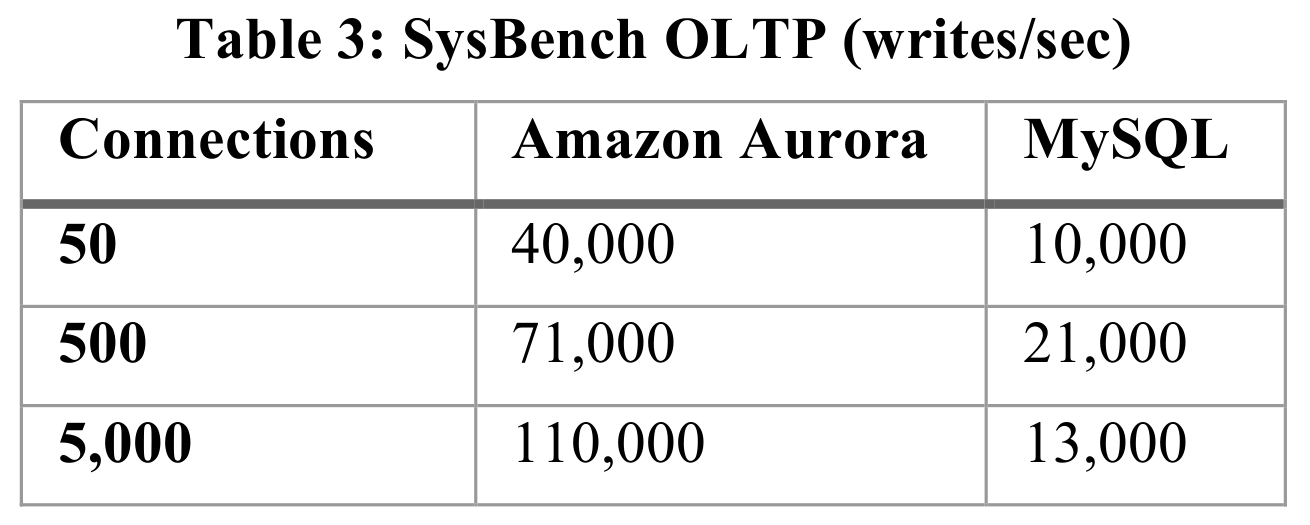
Aurora's TPS increases as the number of connections grows, whereas MySQL's TPS declines sharply after reaching a peak.
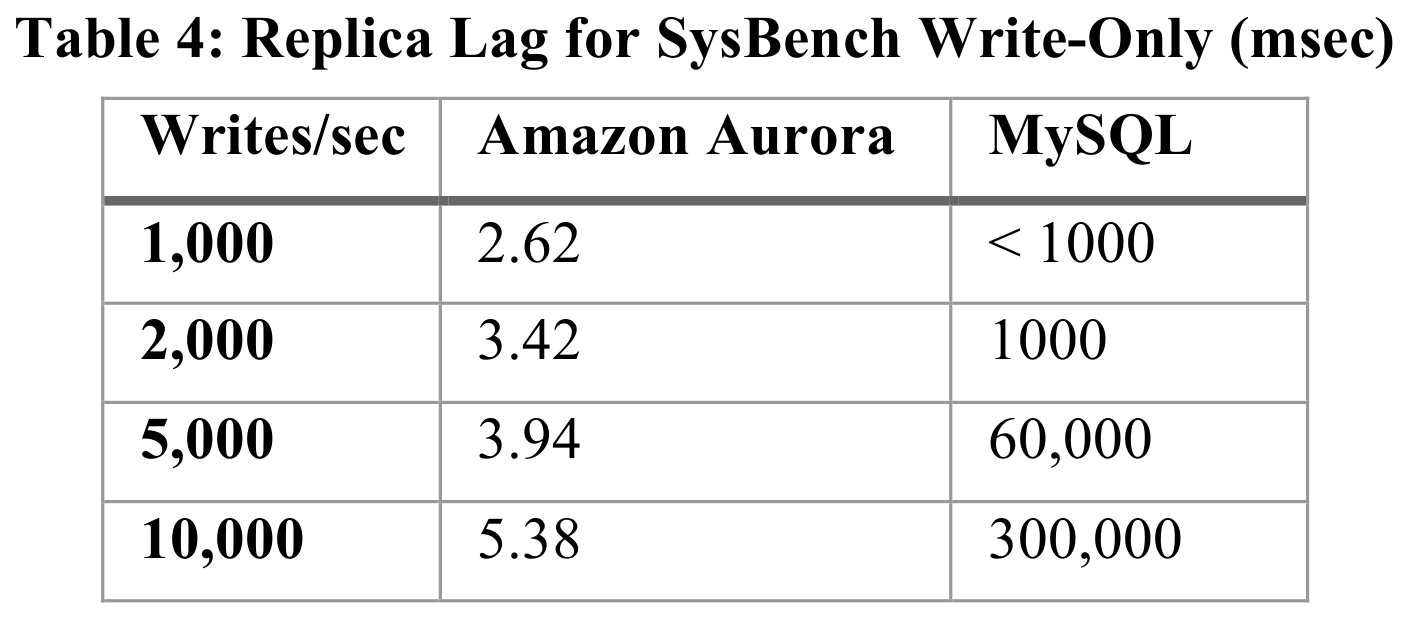
Aurora's replication latency consistently remains at the millisecond level, while MySQL's replication latency is significantly constrained by TPS. This table suggests that MySQL's read replicas are not suitable for read-only tasks that require consistency. In such cases, a read replica can only serve as a backup in case the primary fails. Aurora, however, provides an ideal read/write separation capability, freeing programmers from the mental burden of considering consistency.
Problems with RDBMS
Let's first examine the configuration of a MySQL primary-replica cluster in a cloud environment. The primary and replica instances are placed in different Availability Zones within the same Region. Each instance is attached to a cloud disk, which typically also uses primary-backup replication for disaster recovery. A write request causes various data, such as logs and data pages, to be transmitted across the network in the sequence shown in the diagram. The write request can only complete after these network I/Os finish.
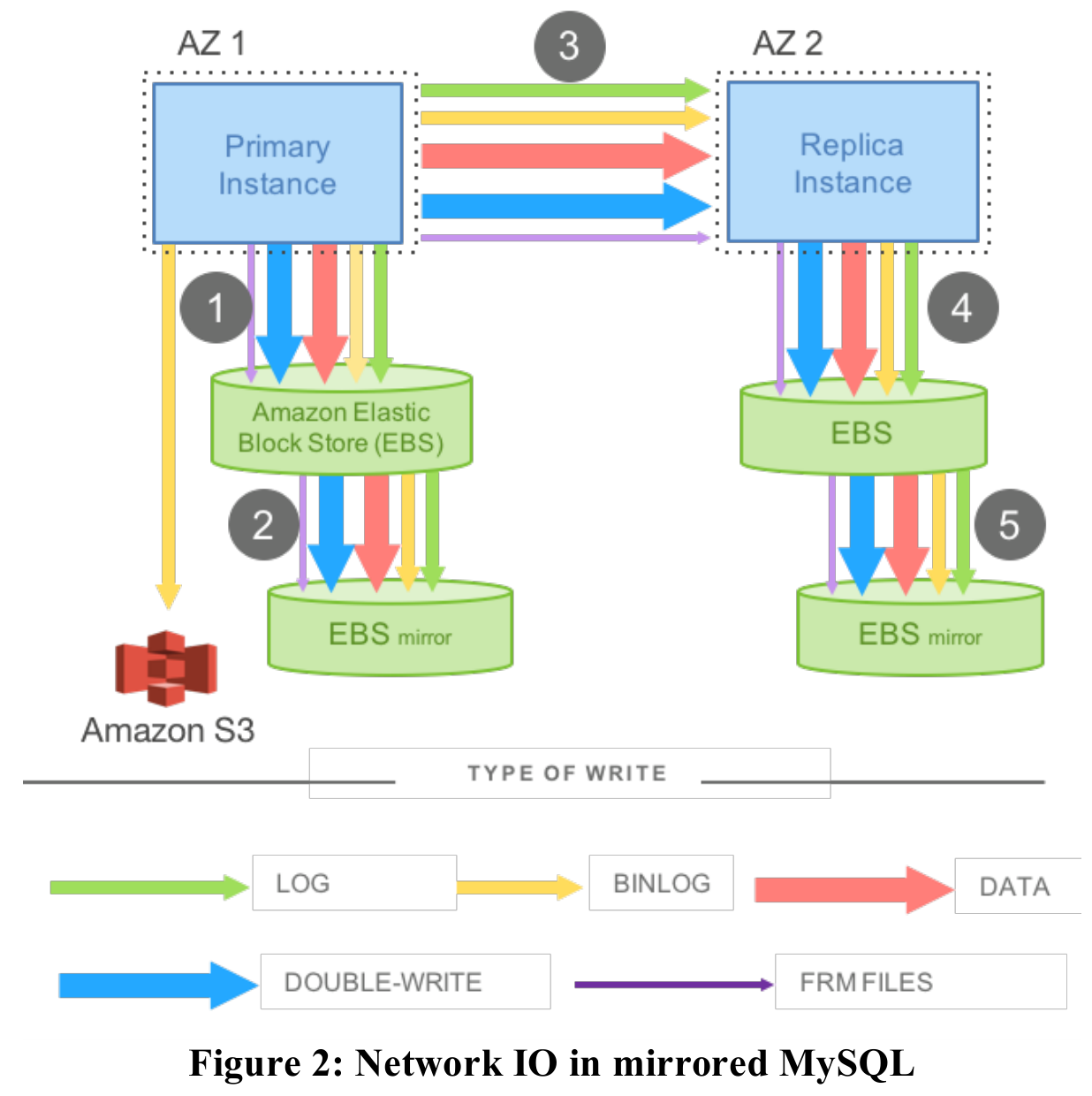
What are the problems with this configuration?
- The network I/O is too heavy, causing a bottleneck. The main reason is that the same data is repeatedly transmitted in various different forms.
- Data replication occurs sequentially, leading to high latency.
Furthermore, in a cloud environment, various issues constantly arise and can interrupt ongoing operations. Operations like two-phase commit for transactions and crash recovery take a long time. If interrupted, they need to be restarted, incurring significant cost.
Thus, RDBMS is not inherently suited for the cloud environment; the cloud's elasticity cannot empower it effectively. However, we can see that the bottleneck of this design largely lies in I/O — previously it was disk, now it's network. Therefore, to implement a truly cloud-native database, we need to analyze the shortcomings of existing storage module designs and introduce improvements and innovations to achieve genuine storage-compute separation.
Aurora Architecture
Aurora adopts a storage-compute separated architecture. The compute nodes are based on MySQL code with modified InnoDB implementation, which delegates the database kernel's logging, storage, and recovery modules to the storage layer. Compute nodes only send redo log records to storage nodes, transmitting no other data. The compute layer still uses primary-replica replication, but the primary node only synchronizes redo logs and metadata files to the replica nodes.
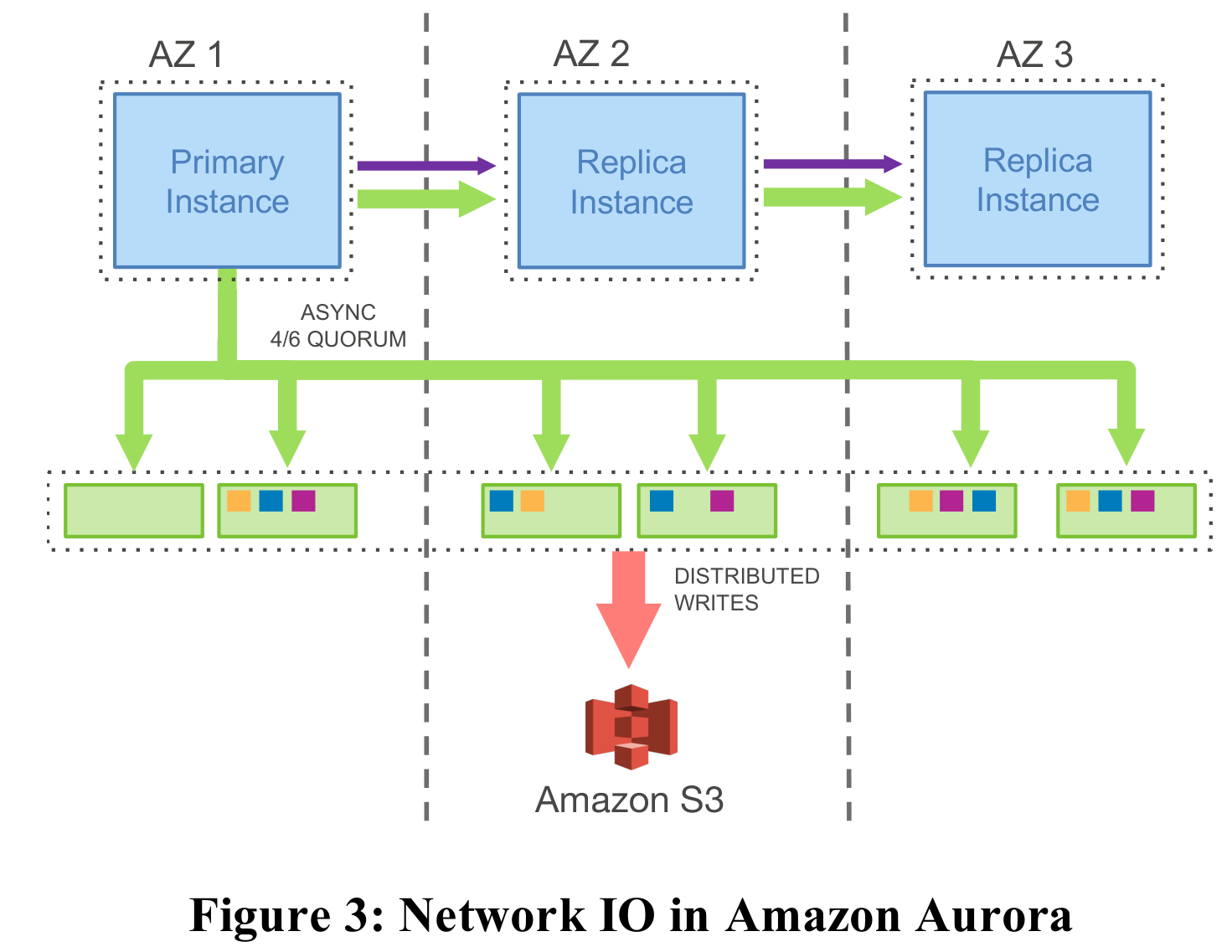
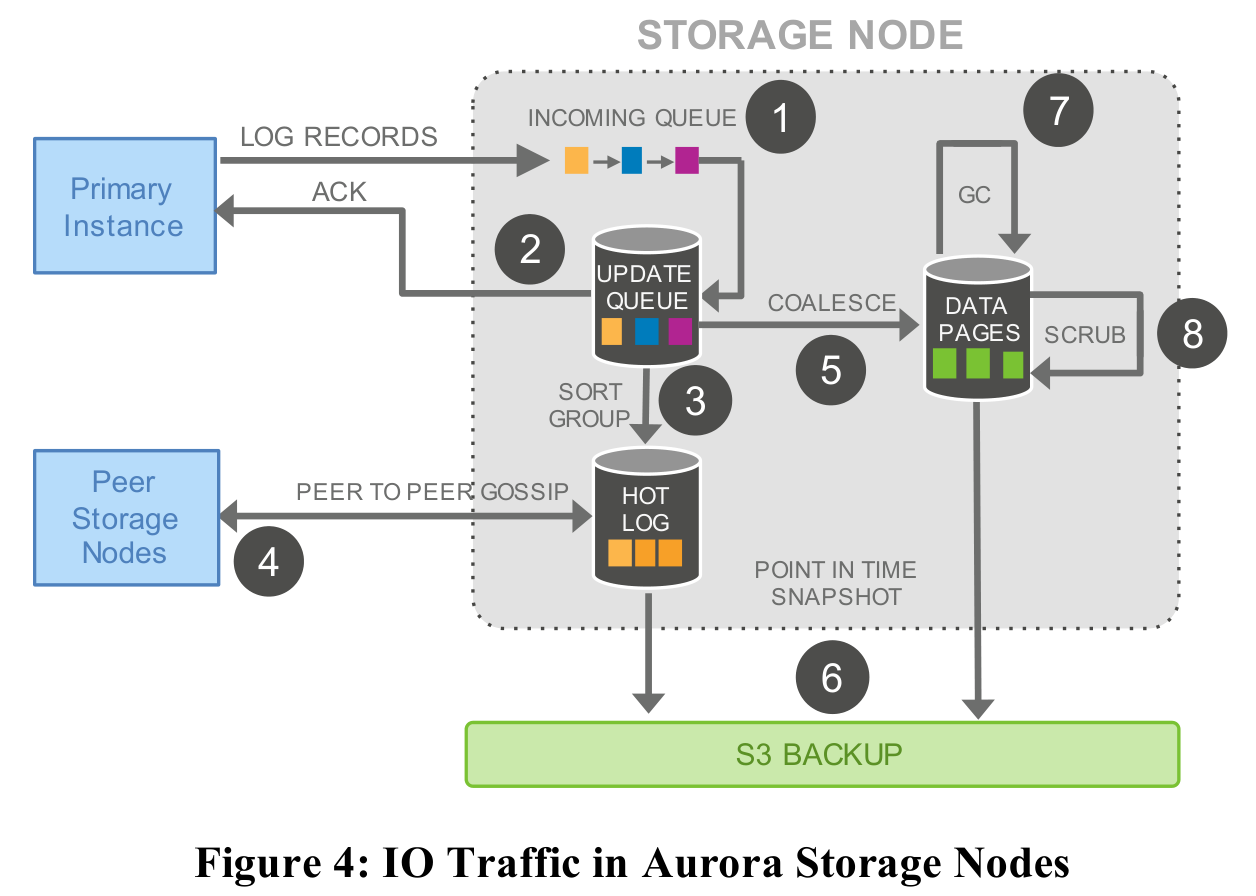
When a storage node receives a log record from a compute node, it immediately acknowledges the write as successful upon persisting it to disk (steps 1 and 2), thereby minimizing latency. Storage nodes perform many operations in the background, including: (1) communicating with other storage nodes to ensure log consistency; (2) consuming logs, applying log records to data pages; (3) periodically performing garbage collection and backup operations.
From Aurora's perspective, the redo log is the database itself; only it needs to be transmitted over the network, while data pages on disk or in memory are merely caches of this log. This approach dramatically reduces network I/O and enables data consistency through consensus algorithms, avoiding inefficient two-phase commit protocols.
Consistency Principles
Aurora's use of redo logs resembles the replicated state machine model. If you've read the Raft paper, the similarity is quite apparent.
The logical representation of an Aurora database's files is a storage volume. Its data is partitioned into multiple fixed-size segments. Each segment is replicated 6 times, with these 6 replica nodes distributed evenly across 3 Availability Zones. These 6 identical segments form a Protection Group (PG), which acts as a logical segment. Therefore, a storage volume is composed of multiple PGs.
Aurora uses a quorum protocol to achieve consistency, with parameters (N, R, W) = (6, 3, 4). The reason for not using the classic (3, 2, 2) configuration (with each replica in a different Availability Zone) is to tolerate the failure of an entire Availability Zone plus one node simultaneously.
Each log record has a globally monotonically increasing sequence number, the LSN (Log Sequence Number), assigned by the compute node to ensure uniqueness. When a compute node writes a log record to the 6 storage nodes, as long as 4 nodes respond with success, the log record is considered durable. Aurora uses the VDL (Volume Durable LSN) to represent the latest durable log record. It follows that any log record with an LSN less than the VDL has been persisted and will not be lost in a crash.
As mentioned earlier, storage nodes frequently communicate with each other to exchange missing log records, ensuring overall log consistency. This differs from most consensus algorithms, as the compute node is not responsible for maintaining the consistency of historical log records among storage nodes. This delegates the work of ensuring overall log consistency to the internal storage layer, reducing network overhead between the compute and storage layers.
Although the quorum protocol requires reading from at least 3 storage nodes for each read, Aurora only does this during data recovery. When handling read requests, the compute node attempts to fetch data from its buffer pool first, based on a condition related to the VDL. On a page fault, it fetches from just one storage node and returns the data to the client. This is done to improve performance but introduces new consistency problems that need handling. Additionally, certain restrictions are necessary during primary-replica replication. Therefore, Aurora employs a mechanism designed around LSNs to ensure data consistency among logs in storage nodes, the buffer pool of the primary compute node, and the buffer pools of replica compute nodes, enhancing performance during normal operations. (However, I didn't fully understand the paper's explanation regarding the principles of maintaining buffer pool and primary-replica consistency, so I cannot reiterate it in this blog post.)
Technical Details
LSN and Transactions
For ease of understanding, the principles related to LSN and VDL mentioned above are highly simplified.
First, the modifications in a log record only pertain to data within a specific segment, so the log records owned by each PG are different. The VDL is calculated based on all the latest LSNs persisted in each PG.
Second, a database typically handles not single write requests but transactions interacting with clients. A database transaction consists of multiple MTRs (mini-transactions), which are ordered. Each MTR contains multiple log records, and an MTR must be executed atomically. The VDL is updated only after an MTR is flushed to disk.
The compute node handles a transaction commit request as follows: upon receiving the request, it generates a log record and blocks the request until the current VDL exceeds that log record's LSN, only then returning commit success to the client. This closely resembles the Raft request handling process, i.e., waiting for a log entry to be applied.
Since the compute node is based on MySQL code, Aurora provides the same transactional capabilities as MySQL (I suspect the transaction module code is largely unchanged).
Crash Recovery
During crash recovery, an RDBMS starts from the last checkpoint, applies all subsequent redo log records up until the point of the crash, and then uses undo logs to roll back incomplete transactions. Applying redo log records is often very time-consuming because checkpoints cannot be taken too frequently to avoid impacting normal transaction processing. Here, redo logs are merely a remedial measure, unrelated to normal data read/write operations.
In Aurora, the log is the database itself. After storage nodes receive log records, they continuously asynchronously modify the relevant data pages (step 5). Here, data pages are effectively snapshots of the logs, avoiding the need to re-execute all log records upon a crash. These snapshots are periodically backed up to S3 and retrieved from S3 during recovery. Additionally, while an RDBMS modifies all pages when applying redo logs, Aurora distributes received log records to the corresponding pages, allowing each page to be recovered individually and multiple pages to be recovered in parallel.
During Aurora's crash recovery, the compute node first communicates with each PG, reading data from at least 3 nodes to determine the latest LSN that is durable for that PG. Based on this LSN information from all PGs, the compute node can calculate the VDL, then instruct storage nodes to truncate any log records with an LSN greater than the VDL, ensuring log consistency. Once this process completes, the compute node can resume normal operation. The work of applying redo log records is handled by storage nodes, and the compute node can apply undo logs while online, so neither step is on the critical path of recovery, significantly speeding up the process.
During crash recovery, the compute node only needs to acquire a small amount of metadata to function normally. Its buffer pool is populated on-demand from storage nodes during normal operation, so it does not consume recovery time.
Storage nodes do not distinguish between normal operation and crash recovery, as the handling process is the same for both: continuously applying log records to data pages. This design is simple and efficient.
Overall Architecture
The previous two diagrams emphasized workflow more than the complete architectural overview.
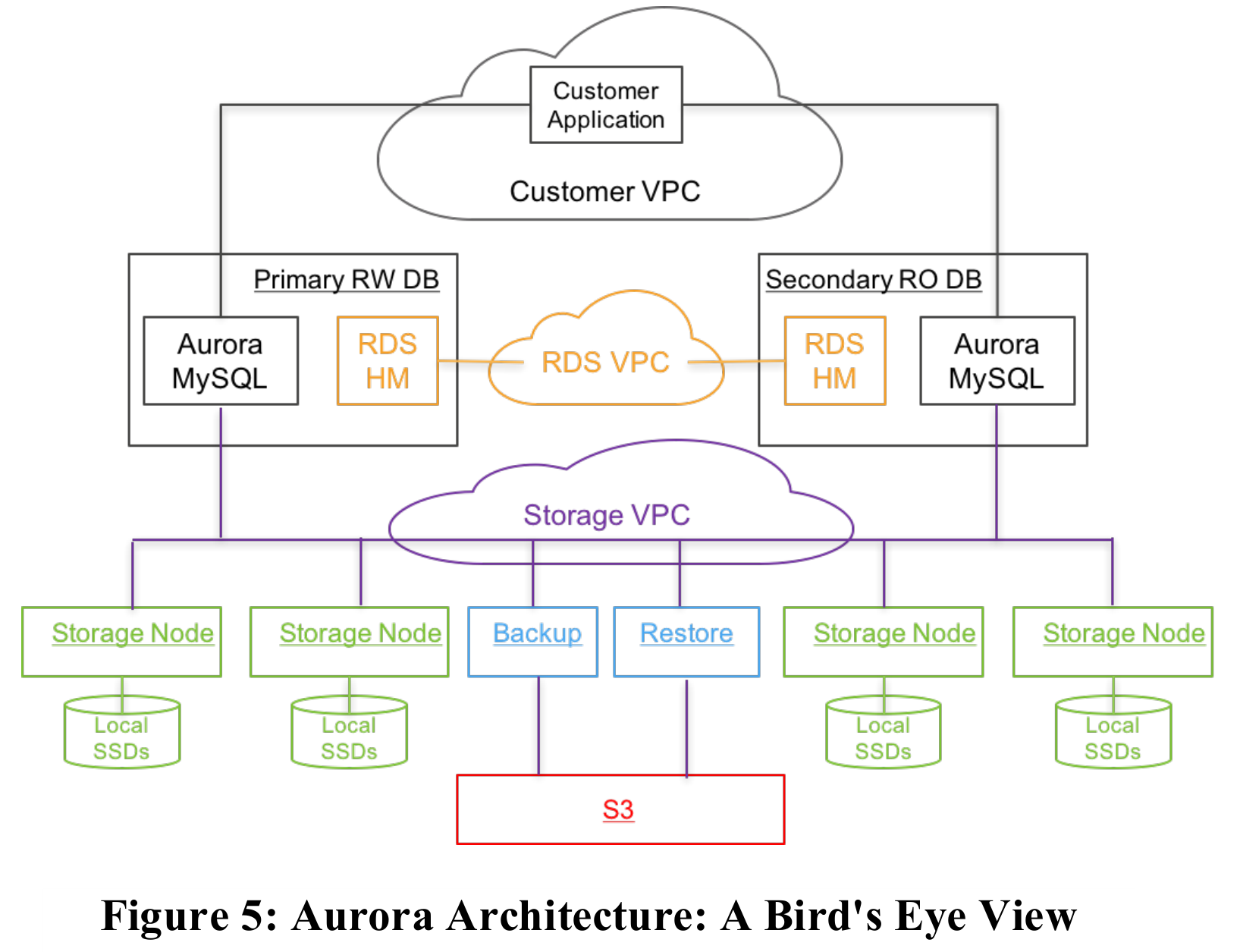
The compute layer uses Amazon RDS (Relational Database Service) as the control plane. A process called Host Manager runs on the compute node machine to monitor compute node status, enabling features like primary-replica failover.
The storage layer's control plane uses Amazon DynamoDB to store metadata for clusters, storage volumes, and backups, and employs monitoring services for automated operations. Storage nodes use SSDs for performance.
It's important to note that the storage layer achieves horizontal capacity scaling by sharding the storage volume using segments. The compute layer, however, uses traditional primary-replica replication. While read performance can be scaled horizontally by adding replica nodes, write performance improvement relies solely on vertical scaling of the primary node. Unlike Spanner, Aurora cannot achieve horizontal scaling of write performance by adding write nodes, which prevents Aurora from being classified as a pure NewSQL database.
References
- Amazon Aurora: Design considerations for high throughput cloud-native relational databases
- LLM